Kubernetes Cluster Autoscaler With IRSA

TL,DR
IRSA is IAM Role for service account. This post shows you how to deploy Cluster Autoscaler as a deployment and assign IRSA for it to provide proper permissions.
Why do we need The Kubernetes Cluster Autoscaler?
The Kubernetes Cluster Autoscaler (CA) is a popular Cluster Autoscaling solution maintained by SIG Autoscaling. While the HPA and VPA allow you to scale pods, CA is responsible for ensuring that your cluster has enough nodes to schedule your pods without wasting resources. It watches for pods that fail to schedule and for nodes that are underutilized. It then simulates the addition or removal of nodes before applying the change to your cluster. The AWS Cloud Provider implementation within Cluster Autoscaler controls the .DesiredReplicas field of your EC2 Auto Scaling Groups.
What’s In This Document
🚀 What is Cluster Autoscaler
Cluster Autoscaler is a tool that automatically adjusts the size of the Kubernetes cluster when one of the following conditions is true:
Some pods failed to run in the cluster due to insufficient resources. Whenever this occurs, the Cluster Autoscaler will update the Amazon EC2 Auto Scaling group to increase the desired count, resulting in additional nodes in the cluster.
There are nodes in the cluster that have been underutilized for an extended period of time and their pods can be placed on other existing nodes. Cluster Autoscaler will then decrease the desired count for the Auto Scaling group to scale in the number of nodes.
🚀 Apply cluster autoscaler deployment in kube-system
On AWS, Cluster Autoscaler utilizes Amazon EC2 Auto Scaling Groups to manage node groups. Cluster Autoscaler typically runs as a Deployment in your cluster.
Download
cluster-autoscaler-autodiscover.yamlfile to update the command point to your EKS cluster and customize expected parameters such as Optimizing for Cost and Availability, Prevent Scale Down Eviction
wget https://raw.githubusercontent.com/kubernetes/autoscaler/master/cluster-autoscaler/cloudprovider/aws/examples/cluster-autoscaler-autodiscover.yaml
Edit the cluster-autoscaler container command to replace (including <>) with your cluster's name, and add the following options.
--balance-similar-node-groups --skip-nodes-with-system-pods=falseHow to run a cluster with nodes in multiple zones for HA?
--balance-similar-node-groupsflag is intended to support this use case. If you set the flag to true, Cluster Autoscaler will automatically identify node groups with the same instance type and the same set of labels (except for the automatically added zone label) and try to keep the sizes of those node groups balanced.This does not guarantee similar node groups will have the same sizes:
Currently, the balancing is only done at scale-up. Cluster Autoscaler will still scale down underutilized nodes regardless of the relative sizes of underlying node groups.
skip-nodes-with-system-podsIf true cluster autoscaler will never delete nodes with pods fromkube-system(except for DaemonSet or mirror pods) we should avoid this for cost optimization.
Check the files at some important fields
ServiceAccount
A version of cluster autoscaler:
cluster-autoscaler:v1.17.3Command
command:
- ./cluster-autoscaler
- --v=4
- --stderrthreshold=info
- --cloud-provider=aws
- --skip-nodes-with-local-storage=false
- --expander=least-waste
- --node-group-auto-discovery=asg:tag=k8s.io/cluster-autoscaler/enabled,k8s.io/cluster-autoscaler/sel-eks-dev
- --balance-similar-node-groups
- --skip-nodes-with-system-pods=false
- Then we apply the yaml file and move to the next step to create IRSA (IAM Role for service account) for the autoscaler deployment
$ kubectl get pod -n kube-system |grep autoscaler
cluster-autoscaler-68857f6759-cwd8b 1/1 Running 0 2d10h
🚀 Create IAM role for service account
Pre-requisite: EKS cluster with OpenID connect, IAM identity provider (Ref to Using IAM Service Account Instead Of Instance Profile For EKS Pods for how to)
Cluster Autoscaler requires the ability to examine and modify EC2 Auto Scaling Groups. We recommend using IAM roles for Service Accounts to associate the Service Account that the Cluster Autoscaler Deployment runs as with an IAM role that can perform these functions.
First create the IAM role which is federated by IAM identiy provider and assumed by
sts:AssumeRoleWithWebIdentity, then attach a policy to provide the permission of autoscaling group for the role. Brief of CDK code in python3:iam_oicis the stack of creating IAM identity provider which is used OIDC as provider,open_id_connect_provider_arnis its attribute from the stack.sel-eks-oic-autoscaler-sa
autoscaler_role = iam.Role( self, 'AutoScalerRole', role_name='sel-eks-oic-autoscaler-sa', assumed_by=iam.FederatedPrincipal( federated=f'{iam_oic.open_id_connect_provider_arn}', conditions={'StringEquals': string_like('kube-system', 'cluster-autoscaler')}, assume_role_action='sts:AssumeRoleWithWebIdentity' ) )
asg_statement = iam.PolicyStatement( effect=iam.Effect.ALLOW, actions=[ "autoscaling:DescribeAutoScalingGroups", "autoscaling:DescribeAutoScalingInstances", "autoscaling:DescribeLaunchConfigurations", "autoscaling:DescribeTags", "autoscaling:SetDesiredCapacity", "autoscaling:TerminateInstanceInAutoScalingGroup", "ec2:DescribeLaunchTemplateVersions" ], resources=['*'], conditions={'StringEquals': {"aws:RequestedRegion": "ap-northeast-2"}} )
autoscaler_role.add_to_policy(asg_statement)
Trust relationships look like:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Federated": "arn:aws:iam::123456789012:oidc-provider/oidc.eks.ap-northeast-2.amazonaws.com/id/<OIDC_PROVIDER_ID>" }, "Action": "sts:AssumeRoleWithWebIdentity", "Condition": { "StringEquals": { "oidc.eks.ap-northeast-2.amazonaws.com/id/<OIDC_PROVIDER_ID>:sub": "system:serviceaccount:kube-system:cluster-autoscaler", "oidc.eks.ap-northeast-2.amazonaws.com/id/<OIDC_PROVIDER_ID>:aud": "sts.amazonaws.com" } } } ] }Next step we annotate the EKS service account
cluster-autoscalerwith this role
🚀 Annotate the EKS service account
- Run the
kubectlcommand
kubectl annotate serviceaccounts -n kube-system cluster-autoscaler eks.amazonaws.com/role-arn=<IAM_role_arn_which_created_above>
- Check the SA
$ kubectl describe sa cluster-autoscaler -n kube-system
Name: cluster-autoscaler
Namespace: kube-system
Labels: k8s-addon=cluster-autoscaler.addons.k8s.io
k8s-app=cluster-autoscaler
Annotations: eks.amazonaws.com/role-arn: arn:aws:iam::123456789012:role/sel-eks-oic-autoscaler-sa
kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","kind":"ServiceAccount","metadata":{"annotations":{},"labels":{"k8s-addon":"cluster-autoscaler.addons.k8s.io","k8s-app"...
Image pull secrets: <none>
Mountable secrets: cluster-autoscaler-token-xxxxx
Tokens: cluster-autoscaler-token-xxxxx
Events: <none>
🚀 Restart the cluster autoscaler pod to take effect
$ kubectl rollout restart deploy cluster-autoscaler -n kube-system
deployment.apps/cluster-autoscaler restarted
We've done setting up the cluster autoscaler but we need to understand some parameters in autoscaler for better choices of Scalability, performance, availability and cost optimization.
🚀 Undestand some Parameters in Autoscaler
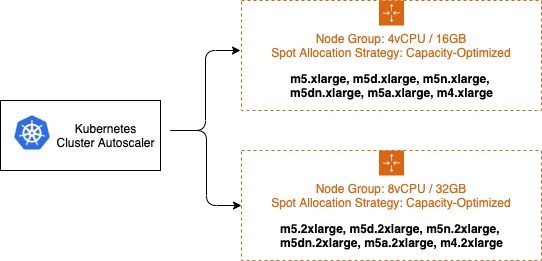
1. Spot instance:
Save up to 90% off the on-demand price, with the trade-off the Spot Instances can be interrupted at any time when EC2 needs the capacity back.
To solve that we should select as many instance families as possible eg. M4, M5, M5a, and M5n instances all have similar amounts of CPU and Memory.
The strategy --expander=least-waste is a good general purpose default, and if you're going to use multiple node groups for Spot Instance diversification (Read more Expanders)
2. Prevent Scale Down Eviction:
Some workloads are expensive to evict such as schedule running reports, cronjob to clear caches or doing backup. The Cluster Autoscaler will attempt to scale down any node under the scale-down-utilization-threshold, which will interrupt any remaining pods on the node. This can be prevented by ensuring that pods that are expensive to evict are protected by a label recognized by the Cluster Autoscaler.
Ensure that: Expensive to evict pods have the annotation
cluster-autoscaler.kubernetes.io/safe-to-evict=false
3. EBS Volumes:
stateful applications such as database or cache which need high availability if sharded across multiple AZs using a separate EBS Volume for each AZ.
Ensure that:
Node group balancing is enabled by setting balance-similar-node-groups=true.
Node Groups are configured with identical settings except for different availability zones and EBS Volumes.
🚀 Basic Test the cluster-autoscaler
- Cluster Autoscaler will respect the minimum and maximum values of each Auto Scaling Group. It will only adjust the desired value.
- Cluster Autoscaler will attempt to determine the CPU, memory, and GPU resources provided by an Auto Scaling Group based on the instance type specified in its Launch Configuration or Launch Template. It will also examine any overrides provided in an ASG's Mixed Instances Policy. If any such overrides are found, only the first instance type found will be used
- In my cluster, I setup the node groud capacity with max_size=2, min_size=1 and desized_size=1, combine with instance types (family type) which ensure the usage of CPU and MEM (r5a.xlarge and r5.xlarge)
add_nodegroup_capacityeks_cluster.add_nodegroup_capacity( id="SelEksNodeGroup", capacity_type=eks.CapacityType.SPOT, desired_size=1, disk_size=20, instance_types=[ec2.InstanceType("r5a.xlarge"), ec2.InstanceType("r5.xlarge")], labels={'role': 'worker', 'type': 'stateless'}, max_size=2, min_size=1, nodegroup_name='sel-eks-node-group', node_role=worker_role, subnets=ec2.SubnetSelection(subnet_type=ec2.SubnetType.PRIVATE) )
1. Test scaleup node: When scaling out all services by setting their replicas > 0 , the cluster-autoscaler detects the need of more node to add more worker.
See its log
I0619 05:56:03.541547 1 scale_up.go:271] Pod dev/stream-58495b5bd6-xjnqk is unschedulable
I0619 05:56:03.541564 1 scale_up.go:271] Pod dev/index-7b747bc884-7zgwh is unschedulable
I0619 05:56:03.541570 1 scale_up.go:271] Pod dev/app-58565d7fbf-ptfpr is unschedulable
I0619 05:56:03.541591 1 scale_up.go:271] Pod dev/nginx-5bbb4f5975-2tg2s is unschedulable
I0619 05:56:03.541596 1 scale_up.go:271] Pod dev/react-index-sink-797f864767-d9tjg is unschedulable
I0619 05:56:03.541643 1 scale_up.go:310] Upcoming 0 nodes
I0619 05:56:03.547721 1 waste.go:57] Expanding Node Group eks-78bcedd4-7ade-c33a-yyyy-xxxxxxxx would waste 37.50% CPU, 79.46% Memory, 58.48% Blended
I0619 05:56:03.547751 1 scale_up.go:431] Best option to resize: eks-78bcedd4-7ade-c33a-yyyy-xxxxxxxx
I0619 05:56:03.547760 1 scale_up.go:435] Estimated 1 nodes needed in eks-78bcedd4-7ade-c33a-yyyy-xxxxxxxx
I0619 05:56:03.550690 1 scale_up.go:539] Final scale-up plan: [{eks-78bcedd4-7ade-c33a-yyyy-xxxxxxxx 1->2 (max: 2)}]
I0619 05:56:03.550716 1 scale_up.go:700] Scale-up: setting group eks-78bcedd4-7ade-c33a-yyyy-xxxxxxxx size to 2
I0619 05:56:03.550746 1 auto_scaling_groups.go:219] Setting asg eks-78bcedd4-7ade-c33a-yyyy-xxxxxxxx size to 22. Test scale down node by scaling down all services. CA will gradually check the cluster and then scaledown the node by set the node to SchedulingDisabled and update auto scaling group.
See the logs
I0619 07:11:46.774322 1 scale_down.go:462] Node ip-10-1-2-3.ap-northeast-2.compute.internal - cpu utilization 0.135204
I0619 07:30:56.486073 1 static_autoscaler.go:428] ip-10-1-2-3.ap-northeast-2.compute.internal is unneeded since 2021-06-19 07:28:35.924053695 +0000 UTC m=+43.074848047 duration 2m20.561420527s
I0619 07:38:38.637225 1 scale_down.go:716] ip-10-1-2-3.ap-northeast-2.compute.internal was unneeded for 10m2.712507047s
I0619 07:38:38.637267 1 scale_down.go:944] Scale-down: removing empty node ip-10-1-2-3.ap-northeast-2.compute.internal
I0619 07:38:38.637418 1 event.go:281] Event(v1.ObjectReference{Kind:"ConfigMap", Namespace:"kube-system", Name:"cluster-autoscaler-status", UID:"78191f9d-4d47-4caa-aa27-xxxxxxxx", APIVersion:"v1", ResourceVersion:"11189392", FieldPath:""}): type:- Check the fleet for canceling the spot instance after scaling down

🚀 How to remove spot instance from cluster manually
- Sometimes cluster autoscaler cannot scale down the node due to eg.
I0619 07:11:46.774431 1 cluster.go:107] Fast evaluation: node ip-10-1-2-3.ap-northeast-2.compute.internal cannot be removed: non-daemonset, non-mirrored, non-pdb-assigned kube-system pod present: aws-load-balancer-controller-597c675c8f-d79h5
To scaledown the node we can cordon the node and rollout restart all deployment/daemonset assign on the node, then let the cluster-autoscaler scaledonw the node.
If you would like to replace a spot instance, flowing reference will help
🚀 Conclusion
- Using Cluster Autoscaler is the best practice in your EKS cluster, one of the most benefit is COST.

- Refs:
https://docs.aws.amazon.com/eks/latest/userguide/cluster-autoscaler.html
https://aws.github.io/aws-eks-best-practices/cluster-autoscaling/cluster-autoscaling/